Introduction to the fuzzy search
When the community implements the Levenshtein algorithm
It is always great to see contributions from our community merged, it reminds the power of working on an open-source project. Especially when there are great features at stake, like the fuzzy search.
In this case, we are talking about the Levenshtein algorithm. It should be available in version 1.7.7 thanks to Lathanao and it will definitely improve both the user experience and the conversion rate on your site! Wow, but what is it? It is a component that will improve the PrestaShop search functionality by taking into account misspelling or error inputs.
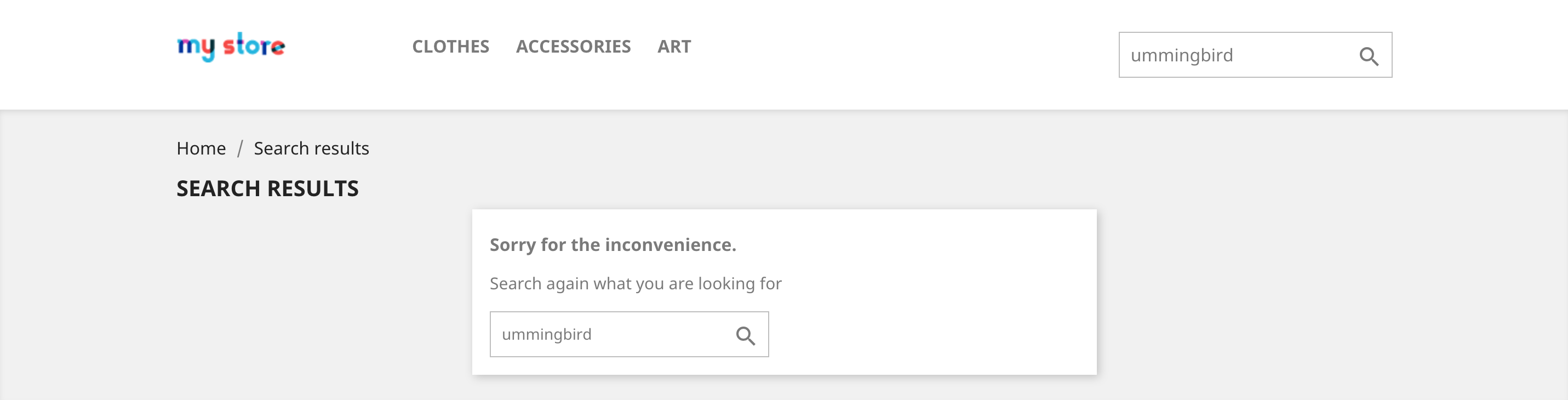
Let us say a customer wants to buy the ‘hummingbird printed sweater’ item in the catalog, he is in a rush so he pounces on the search bar and types ‘ummingbird’, hoping to get an instant result. And there is no result because of the lacking ‘h’. Such a situation will not happen with the Levenshtein algorithm since the search controller can find the closest word (‘hummingbird’ in this case) and display all ‘hummingbirds’ items as results.
Now, let us dive into the development of this feature:
📫 About the Levenshtein algorithm
From a technical point of view
Putting it simply, the Levenshtein algorithm (used in the case of the fuzzy search) computes very quickly how many differences there are between two strings; this difference is called ‘distance’. In order to give you an idea of how PHP works fast, note that its processing time to calculate 2,000 words is about 0.01 second - depending on your server also, of course.
For example, this approximate string matching allows you to calculate that between ‘ummingbird’ and ‘hummingbird’, the distance is 1. A search using this algorithm is commonly called a fuzzy search. You can play with PHP’s levenshtein function and try to understand how it works.
Enough theory, let us return to the Prestashop modification! So here, the goal is to compare the query with words included in the database. All this process is performed with a new static method called findClosestWord(). And since it is static, you can call it wherever you want. ;-)
While examining this method, you can see we have included an autoscale algorithm. Why so? Because one problem was there were stores with large catalogs that contain more than one million referenced words in their database! In those cases, it takes a lot of computation to compare every word.
The idea is we probably do not want to compare every word: comparing the long query ‘ummingbird’ with the short word ‘mug’ is indeed not relevant at all. In fact, search should only compare short queries to short words and long queries to long words.
How does it work?
So, the first part of the method sorts by length a batch of words in order to keep relevant computed Levenshtein distance and therefore have fewer words to compare. Indeed, fewer words to compare means less server stress and faster search results.
Once the query string is sent to the search provider, three logic processes compute:
Phase 1: the search provider retrieves products depending on relevant keywords in ps_search_words.
Note that ps_search_words stands for the SQL table where indexed words for search are stored. In other words, this is a table in the database.
Here, if the fuzzy search is not enabled and the query contains misspelling errors, your chance to get relevant products are very weak.
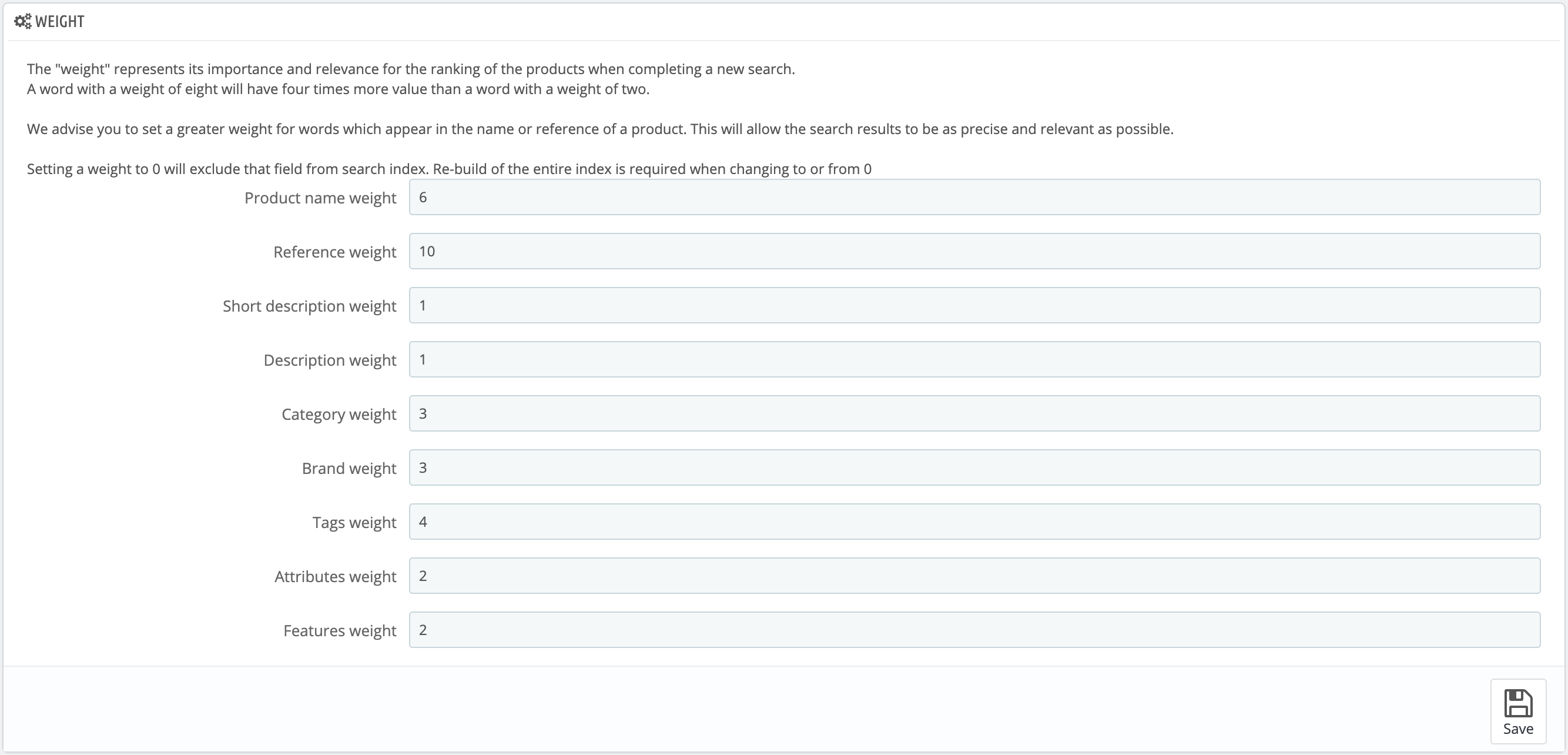
At this step, a sort by weight is done. Remember that you can increase your search accuracy by setting up word weight in the Shop Parameters > Search > Weight section of the back office.
Phase 2: the search provider selects products depending on conditions (availability, visibility, etc.).
If more than one keyword is queried, the search provider merges different relevant products from each word query.
Phase 3: the search provider reports products with all necessary information (price, name, etc.), then returns results in the front office.
Here, we can understand that, in the first phase (the one containing a misspelling error), no word will be brought. Consequently, phases 2 and 3 will not be executed. So when no word is reported, the idea is to check if a word in the database is close enough to the query, to continue the search process. In our example, ‘ummingbird’ is close to ‘hummingbird’. Easy!
Hopefully, this problem is common and PHP includes a library that solves this problem. A library that is called Levenshtein. And the algorithm is called the Levenshtein distance. Rings a bell? ;-)
📬 Inside the code
In order to deduct what word is the most relevant, we use a common PHP functionality: levenshtein(). This method is already included in PHP by default. Written in C language, the computation is really fast.
In rare cases, no relevant word is returned. In those cases, the default search behavior is applied, and no search results are returned.
Setting up the distance
NOTE
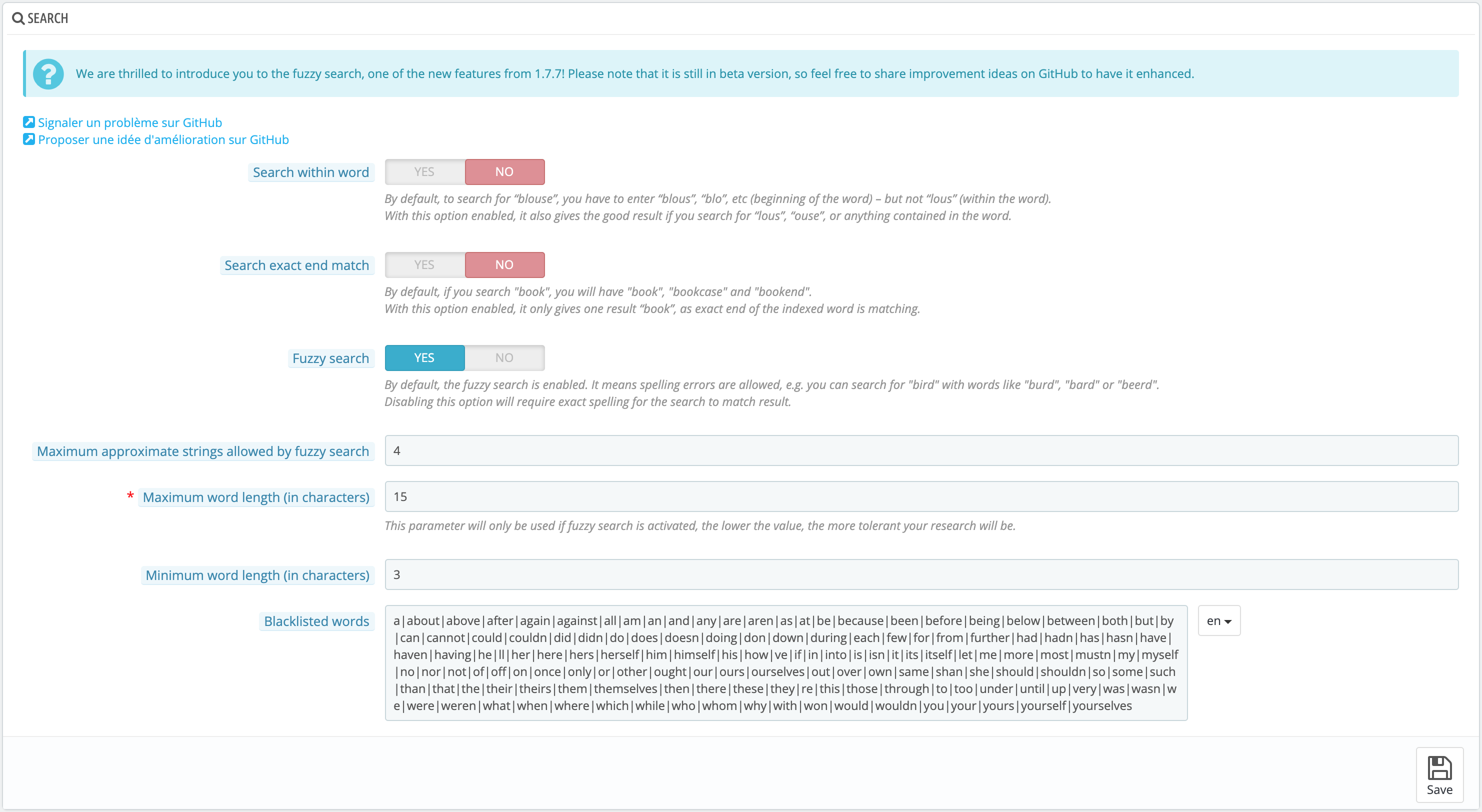
Here, this configuration has no influence on the server stress, the setup being active right after computation.You must be in the code to configure it - it is not available in the back office -, search for PS_DISTANCE_MAX in the classes/Search.php file. By default, the value is set to 8 which is typically the maximum distance to get a relevant result. Every fuzzy search returns a word with a distance under 8. It means the fuzzy search will try to bring words that are close to the query.
For instance, without this distance limitation, query ‘ummingbird’ could return ‘xxxxx’ if ‘xxxxx’ gets the best distance than all other words in the database. But this is nonsense. Also, getting irrelevant search results will obviously decrease the user experience on the store. Hence this limitation.
For all these reasons, we concluded that 8 was the right distance both in terms of search results and UX.
Go play and adjust the distance in the search class following this rule:
Between 1-4, the distance allows only too few errors: this setup does not stress the server and can give a better error margin.
Between 4-7, the distance is perfect for Latin languages with short words: only light misspelling errors are allowed, but it happens in special cases.
Let us go a little bit deeper…
So 8 is a good distance for English, French or other Latin languages’ words: big spelling mistakes get a result but, in some cases, we can get irrelevant results. Perfect combination!
Between 9-10 is a good distance to extend the result without getting only totally irrelevant results. Here, user experience starts to decrease.
Beyond 10, too many results will be irrelevant and the user experience decreases seriously.
You can still try to increase this limit for languages whose words are especially long, like the German.
Setting up the maximum approximate strings allowed
NOTE
Here, this configuration influences the server stress in case of big queries including many words.Configuring it allows you to define the number of words a query can be processed in a fuzzy search. By default, the value is set to 4. It means that in a search like ‘Samsung Galaxi walle cherger multyplug’, only the ‘Samsung’, ‘Galaxi’, ‘walle’, and ‘cherger’ words will be taken into account. ‘Multyplug’ will not be computed.
Why this limitation? It is to avoid offensive behaviors (from users or others) on the store that could overstress the server intentionally. We keep the possibility to reduce this number but most stores will not have to do so.
Setting up the maximum word length allowed
NOTE
Here, this configuration influences the server stress in case of long words queries.So this option defines how many characters you allow to execute a fuzzy search query. You can configure it only when the fuzzy search is enabled. When the feature is disabled, the default parameter is set to 30, particularly to solve this issue cf. #12407. You can set this value directly in the back office while the default value is a constant defined in the code, in the search class, just like the maximum distance allowed.
In the case of broad databases, you should decrease the value to 10-14 in order to decrease both server stress and response time. Under 10, the result is likely to be irrelevant. Indeed, the longer the word (in characters), the more stressed the server is. We advise the number of 15 to keep the fuzzy search fast, even when processing long queries.
Do not forget the Levenshtein algorithm is a matrix computation: the server stress increases exponentially just because it’s depending on the square (about) of the query length.
Setting up the minimum word length allowed
NOTE
Here, this configuration influences the server stress.It is no special feature included in the fuzzy search but a mere parameter, set to 3 by default. In other words, this configuration does not read words whose length is less than three characters. If you need deeply precise results, like with ‘Samsung S9’, you should decrease the minimum allowed to 2 because ‘S9’ only has two characters.
📭 Conclusion
Time is now. And now, more than half of the customers find online stores on a mobile device (read). And those people will look for the product they want by using your search feature.
More info? Be aware that half of the queries contain misspelling errors - just look at the Stats > Shop search section of the PrestaShop back office. So there is a huge need to improve the effectiveness of your search results by getting more quality, especially when you know that queries are typed on devices where misspellings are easy to make (read).
In short, a problem that is common to million shop owners and developers. Sadly. But the good thing is that we can improve that! Indeed, the IT market has seen new kinds of products like Algolia or ElasticSearch modules popping up. A quick look at how they work is enough to conclude that they combine three main characteristics: they search fast, they offer qualitative results and they are misspellings compliant. From a PrestaShop point of view, this new Levenshtein feature helps you get the same benefits:
Faster search. Getting a result with the PrestaShop’s default search provider is fast today. More performance will not improve the UX that much, but it might later.
Qualitative results. From the start, PrestaShop and its ecosystem worked to get the most effective search result. Even if the default Prestashop configuration suits all shops, you can now increase again the quality of the results obtained by setting up a coefficient with the weight parameters (see screenshot above). This system is strongly inspired by the most effective search engine document classification methods, and allows you to classify the keywords of your product pages by importance: focus first on the title, the categories, the description, etc.
Misspellings compliant. Algolia, ElasticSearch, and even Google are errors compliant. Why not PrestaShop? If, before, the default search provided wasn’t misspellings compliant, it is now, it is done, and it works very well.